- di Giancarlo Manfredi, Disaster Manager – “Di cosa parliamo se ci riferiamo ad un algoritmo quando si tratta di gestire il rischio? In breve, ad un diagramma che rappresenta visivamente i rischi associati ad un determinato processo, tenendo in considerazione la gravità di esiti nocivi e la loro relativa probabilità di accadimento in termini crescenti. Parlando di SARS-CoV-2, il problema, allo stato attuale, è che possiamo conoscere i dati pubblicati settimanalmente sul sito dell’Istituto Superiore della Sanità, ma non conosciamo il diagramma di flusso che governa l’algoritmo. C’è poi un secondo “guaio”, quello circa l’affidabilità dei dati: abbiamo infatti compreso, fin dalla prima ondata pandemica, come la rilevazione dei parametri significativi sia stata condizionata da pesanti bias qualitativi e quantitativi: mancanza di standard unici nazionali, sistemi di rilevazione inadeguati al processo, granularità del dato insufficiente, organismi di tracciatura che raggiungono la saturazione, una maggiore necessità di chiarezza e condivisione, l’assenza di un sistema continuo (ovvero che segue nel tempo le varie coorti o cluster identificati) di rilevazione nazionale su base campionaria …”

«Non solo nella ricerca biologica ma anche nel quotidiano di politica ed economia le cose sarebbero molto migliori se si comprendesse che semplici sistemi non-lineari non possiedono necessariamente proprietà dinamiche semplici». (Robert May [1], 1989)
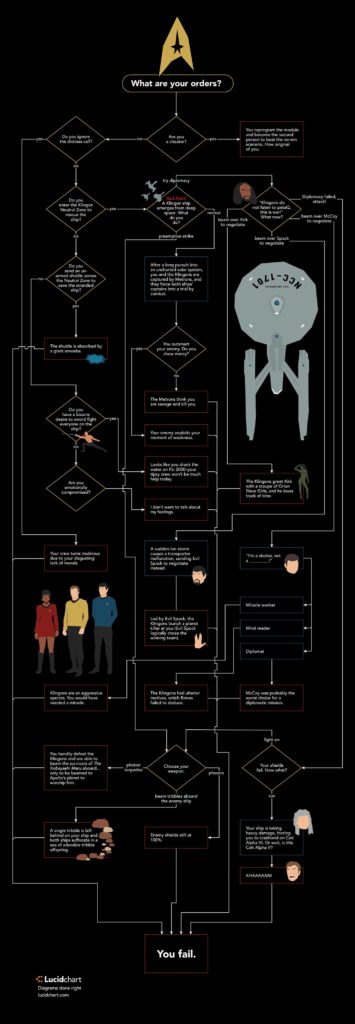
Nell’universo immaginario raccontato dalla saga fantascientifica di #StarTrek, il test della #KobayashiMaru [2] è il classico #NoWinScenario, ovvero è un test attitudinale cui vengono sottoposti, attraverso una simulazione immersiva, tutti i cadetti della Flotta Stellare che devono decidere – in tempo reale e con poche informazioni certe – tra una serie di opzioni, nessuna delle quali però comporta in realtà la sopravvivenza dell’astronave e dell’equipaggio.
Parliamo di “cultura pop”, nulla apparentemente a che vedere con la #TeoriaDelleDecisioni [3] o con le tecniche della #CrisisManagement, tuttavia si tratta di scenari che non sono affatto alieni alla vita reale: prendiamo ad esempio il settore della #ProtezioneCivile e dei meccanismi che governano la gestione delle cosiddette #MaxiEmergenze, eventi di rilevante intensità, dimensione e perdurata, che necessitano di scelte governative importanti – spesso letteralmente vitali – quanto drammatiche.
Ecco allora il documento pubblicato lo scorso 10 novembre sul sito del Ministero della Sanità in merito ai 21 parametri distinti in 3 categorie [4] che descrivono (un po’ come avviene sui monitor della plancia di comando dell’astronave Enterprise nella simulazione descritta pocanzi) lo stato in tempo reale dell’epidemia di Covid-19 su base regionale.
E’ forse la prima volta che un governo italiano si affida per le proprie decisioni (sulla vita di cittadini e aziende) a una serie di indicatori statistici: stiamo forse andando verso una politica cosiddetta #DataDriven, ovvero guidata non solo da principi ideologici, ma in base a dati e algoritmi consolidati e analizzati su base scientifica?
Il rischio implicito è, ovviamente, quello di assistere, piuttosto, ad una deresponsabilizzazione, se non ad una cessione di sovranità della leadership di fronte a scelte che comportano, in ogni caso, delle controindicazioni.
Ma di cosa parliamo quando ci riferiamo ad un algoritmo quando si tratta di gestire il rischio?
In realtà questi (famigerati ancorché poco noti) algoritmi si riconducono al concetto di #MatriceDelleProbabilità [5], ovvero ad un diagramma che rappresenta visivamente i rischi associati ad un determinato processo, tenendo in considerazione la gravità di esiti nocivi e la loro relativa probabilità di accadimento in termini crescenti.
Nello specifico parliamo della minaccia sanitaria costituita dalla trasmissione non controllata e non gestibile di SARS-CoV-2 (ma potrebbe trattarsi dei sintomi precursori di una eruzione vulcanica nell’area flegrea e della necessità di ordinare un’evacuazione massiva dalle “zone rosse”), il problema, allo stato attuale, è che possiamo conoscere i dati [6], pubblicati settimanalmente sul sito dell’Istituto Superiore della Sanità, ma non conosciamo il diagramma di flusso che governa l’algoritmo [7].
C’è poi un secondo “guaio”, quello circa l’affidabilità dei dati: abbiamo infatti compreso, fin dalla prima ondata pandemica, come la rilevazione dei parametri significativi sia stata condizionata da pesanti bias qualitativi e quantitativi: mancanza di standard unici nazionali, sistemi di rilevazione inadeguati al processo, granularità del dato insufficiente, organismi di tracciatura che raggiungono la saturazione, una maggiore necessità di chiarezza e condivisione [8], l’assenza di un sistema continuo (ovvero che segue nel tempo le varie coorti o cluster identificati) di rilevazione nazionale su base campionaria [9]…
Un quadro insomma che comporta la sottovalutazione del fenomeno, la sua descrizione parziale, spesso tardiva, e una generalmente scarsa significatività quando invece abbiamo di fronte uno scenario complesso: pensiamo solo a tutti meccanismi fisici e biologici, socio-economici, sanitari e demografici che governano una pandemia, un contesto statistico dove l’infetto (il dato stesso da rilevare) è sia causa che effetto del processo stesso !!!
Vero, se parliamo di decisioni guidate dai dati, oggi abbiamo le conoscenze e le tecnologie e i flussi informativi [10] per accumulare enormi quantità di informazioni: domandiamoci però se, allo stato dell’arte, abbiamo anche le conoscenze per elaborare in modelli concreti (parliamo di sistemi non lineari di equazioni differenziali!!!) della complessità, come già anticipava oltre trent’anni fa il fisico ed ecologista Robert May nel suo documento “The Guidelines on the Use of Science and Engineering Advice” sull’utilizzo da parte della politica delle consulenze scientifiche.
Ed infine c’è il discorso, per nulla banale, dell’#EticaDellaLeadership: come per il test della Kobayashi Maru, anche nel caso della pandemia (o dell’eruzione del Vesuvio) ci sono decisioni che vanno oltre la mera regola giuridica e che l’algoritmo non sa prendere e che non deve prendere: ben al di là dunque delle problematiche (pur esistenti) relative al rispetto della privacy [11], la cosiddetta “programmazione tecnologica” deve essere solo un supporto decisionale a chi deve decidere della vita (e talvolta della morte) e nessun algoritmo, per quanto automatismo efficace nei processi di pianificazione della gestione del rischio, può trasformarsi in una forma di evasione dalle responsabilità.
P.S. Si sa che il Capitano Kirk è l’unico cadetto della Flotta Stellare ad aver mai superato il test della Kobayashi Maru, ma questo solo perché ha barato riprogrammando l’algoritmo…
Fonti e link per approfondire
[1] https://ilbolive.unipd.it/index.php/it/news/lord-robert-may-fisico-ecologista-che-guardava
[2] https://it.wikipedia.org/wiki/Test_della_Kobayashi_Maru
[4] http://www.salute.gov.it/imgs/C_17_notizie_5152_1_file.pdf
[7] http://www.vita.it/it/article/2020/11/06/regioni-appese-a-un-algoritmo-che-nessuno-ha-visto/157261/
[8] https://www.infodata.ilsole24ore.com/2020/03/20/open-data-coronavirus-litalia-delle-regione/
[10] https://ilbolive.unipd.it/it/news/possiamo-usare-dati-web-combattere-pandemia [11] https://www.agendadigitale.eu/sicurezza/privacy/etica-e-trattamento-dati-cosi-si-sconfigge-la-dittatura-dellalgoritmo/